
We use cookies to ensure our website works properly and to personalise your experience. Cookies policy
Department of Pharmacy Practice, Vels Institute of Science, Technology & Advance Studies, Chennai, Tamil Nadu
Pharmacovigilance (PV) is the science and activities relating to the detection, assessment, understanding, and prevention of adverse drug reactions (ADRs) and other drug-related problems. The exponential growth in global drug utilisation combined with the proliferation of electronic health records (EHRs), social media, and spontaneous reporting systems has generated unprecedented volumes of safety data that strain traditional manual review workflows. Regulatory frameworks such as the International Council for Harmonisation – Good Clinical Practice (ICH-GCP) E2A–E6 series, the European Medicines Agency (EMA) pharmacovigilance legislation, and the FDA Sentinel System mandate rigorous, timely, and reproducible signal management processes. This article systematically reviews the application of artificial intelligence (AI) and machine learning (ML) methodologies – including natural language processing (NLP), deep learning, graph neural networks, and Bayesian statistical methods – in ADR detection, signal management, and benefit–risk assessment, with emphasis on regulatory compliance under ICH-GCP. Methods: A structured literature search was conducted across MEDLINE, EMBASE, Cochrane Library, and WHO-VigiBase publication catalogues for the period 2010–2024. Seventy-eight peer-reviewed studies, regulatory guidance documents, and technical whitepapers meeting predefined inclusion criteria were analysed. Methodologies were categorised by AI/ML technique, data source, regulatory context, and performance metrics. AI/ML systems demonstrate superior performance compared with classical disproportionality analyses in ADR signal detection, with AUROC values ranging from 0.82 to 0.97 across validated datasets. NLP-based pipelines applied to EHR free-text achieved F1 scores of 0.78–0.91 for ADR entity recognition. Large language models (LLMs) show promise for automated narrative medical case summarisation and MedDRA coding. Implementation challenges include algorithmic transparency, data heterogeneity, and harmonisation with ICH-E2B(R3) electronic reporting standards. AI and ML are transforming pharmacovigilance by enabling earlier, more sensitive, and scalable ADR signal detection. Successful integration into GCP-compliant workflows requires regulatory-grade model validation, auditability, and explainability frameworks. Prospective collaboration among industry, regulators, and academia is essential to establish harmonised standards for AI-augmented pharmacovigilance.
Pharmacovigilance (PV) is defined by the World Health Organization (WHO) as "the science and activities relating to the detection, assessment, understanding and prevention of adverse effects or any other medicine-related problem."[1] The global burden of ADRs is substantial: estimates suggest that ADRs account for 5–10% of all hospital admissions in developed countries, contribute to approximately 197,000 deaths annually in the European Union alone, and impose direct healthcare costs exceeding USD 30 billion per year in the United States.[2,3]
Spontaneous reporting systems (SRS) — including the FDA Adverse Event Reporting System (FAERS), the WHO-VigiBase, and the EMA EudraVigilance database — have historically served as the backbone of global signal detection. By 2024, FAERS contained more than 25 million reports, VigiBase accumulated over 35 million individual case safety reports (ICSRs), and EudraVigilance held approximately 22 million records.[4,5] While SRS provide invaluable real-world safety data, they are afflicted by under-reporting estimated at 90–95% in many countries, reporting bias, inconsistent data quality, and inherent time lag between ADR occurrence and regulatory action.[6]
The integration of EHRs, patient registries, insurance claims databases, genomic repositories, and social media platforms into pharmacovigilance workflows has created the "Big Data" landscape of drug safety. The sheer volume, velocity, and variety of these data streams have rendered traditional manual pharmacovigilance activities computationally intractable without technological augmentation.[7,8]
Artificial intelligence (AI) and machine learning (ML) offer transformative potential. By automating text mining, predictive modelling, and signal prioritisation, AI systems can enhance sensitivity, specificity, and throughput of ADR detection while reducing reviewer workload. Natural language processing (NLP) pipelines can mine unstructured clinical notes and social media posts for ADR signals invisible to classical disproportionality analyses. Deep learning models can discover complex pharmacological interactions and patient-specific risk factors that correlate with ADR occurrence.[9,10]
However, deployment of AI/ML in regulated pharmacovigilance introduces novel challenges related to model validation, transparency, reproducibility, and regulatory compliance. The ICH-GCP guidelines — ICH E2A, E2B(R3), E2C(R2), E2E, and E6(R2) — establish the foundational regulatory framework within which AI-augmented pharmacovigilance must operate.[11,12,13,14,15] The EMA draft reflection paper on AI in drug development (2023) and the FDA AI/ML-based Software as a Medical Device (SaMD) action plan further underscore the urgency of developing harmonised standards for responsible AI deployment in drug safety.[16,17]
This comprehensive review synthesises the current state of AI and ML applications in pharmacovigilance, examining their methodological underpinnings, performance benchmarks, regulatory implications, and implementation challenges. We address ADR detection from multiple data modalities, automated signal management, benefit–risk assessment augmentation, and the specific requirements for ICH-GCP compliant deployment of AI-based pharmacovigilance tools. Our analysis draws on 78 peer-reviewed studies, regulatory guidance documents, and technical reports published between 2010 and 2024.
BACKGROUND AND REGULATORY FRAMEWORK
Historical Evolution of Pharmacovigilance
The thalidomide tragedy of 1961, in which approximately 10,000 children were born with phocomelia following maternal use of the drug as a sedative during the first trimester of pregnancy, catalysed the modern pharmacovigilance movement.[18] This catastrophic ADR prompted establishment of voluntary SRS by regulatory agencies worldwide. The FDA introduced its mandatory reporting programme in 1962 under the Kefauver-Harris Amendment, while the WHO Programme for International Drug Monitoring was established in 1968 to facilitate international data sharing.[19]
The subsequent decades witnessed progressive institutionalisation of PV obligations. The Medical Dictionary for Regulatory Activities (MedDRA) controlled vocabulary, adopted globally in the late 1990s, enabled standardised ADR coding across regulatory submissions.[20] The early 2000s heralded systematic application of statistical signal detection methodologies, including the proportional reporting ratio (PRR) developed by Evans et al.,[21] the Bayesian Confidence Propagation Neural Network (BCPNN) pioneered at the WHO-Uppsala Monitoring Centre (WHO-UMC),[22] and the Multi-Item Gamma Poisson Shrinker (MGPS) algorithm.[23]
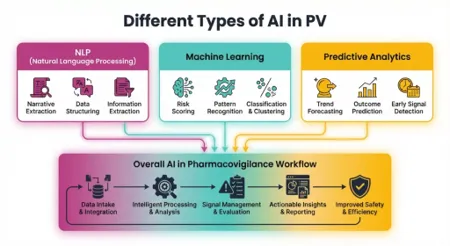
FIG 1 TYPES OF PV
The reporting odds ratio (ROR) described by Bate and Evans[24] and the empirical Bayes geometric mean (EBGM) within the MGPS algorithm[23] remain foundational to current regulatory signal detection practice. These methods represented the first automated approaches to identifying statistical associations between drugs and ADRs within SRS databases and remain widely used despite the emergence of more sophisticated AI/ML approaches.
ICH-GCP Regulatory Framework for Pharmacovigilance
The ICH-GCP guidelines constitute the overarching regulatory framework governing clinical research and post-marketing drug safety activities across the United States, European Union, Japan, Canada, and over 50 associated countries. ICH E2A (1994) defines clinical safety data management and obligations for expedited reporting of serious unexpected suspected adverse reactions (SUSARs), establishing the minimum dataset for a valid ICSR.[11]
ICH E2B(R3) (2013, implemented 2017) specifies the electronic data interchange format for ICSR transmission, introducing HL7 FHIR-compatible messaging standards and expanded data elements underpinning EudraVigilance, FAERS, and VigiBase data exchange.[12] ICH E2C(R2) (2012) governs the structure and content of Periodic Benefit-Risk Evaluation Reports (PBRERs), requiring systematic characterisation of the evolving benefit–risk profile of approved medicinal products at defined intervals.[13]
ICH E2E (2004) provides guidance on pharmacovigilance planning, including the Pharmacovigilance Plan (PVP) and Risk Management Plan (RMP).[14] ICH E6(R2) (2016) specifies quality system requirements applicable to clinical investigation, including data integrity, audit trails, and electronic system validation requirements with direct relevance to AI/ML systems used in pharmacovigilance.[15] The EMA Good Pharmacovigilance Practice (GVP) modules I–XVI provide detailed operational guidance across all PV activities.[25]
Classical Signal Detection and Its Limitations
Classical statistical signal detection relies on disproportionality analysis (DA) applied to SRS data. The two-by-two contingency table at the heart of DA compares the observed number of reports for a specific drug-ADR pair against the expected number derived from the background reporting rate. The PRR threshold commonly applied is PRR ≥ 2 with χ² ≥ 4 and at least 3 reports.[21]
While computationally efficient and interpretable, classical DA methods suffer from fundamental limitations. The masking effect — wherein a strong signal for one drug suppresses detection of a weaker signal for another drug for the same ADR — can conceal genuine safety concerns.[26] Traditional DA ignores temporal patterns, dose–response relationships, patient characteristics, and drug interaction effects. Reporting biases including the notoriety effect, Weber effect, and channelling bias further compromise signal validity.[26] These structural limitations motivate the development of AI/ML-based approaches.[9]
AI AND MACHINE LEARNING METHODOLOGIES IN PHARMACOVIGILANCE
Natural Language Processing for ADR Detection
Natural language processing represents the most extensively applied AI technology in pharmacovigilance. The majority of clinically relevant safety information resides in unstructured text: clinical notes, discharge summaries, pathology reports, autopsy findings, literature case reports, patient forums, and social media posts. NLP systems can process millions of text documents in hours, applying rule-based, statistical, and neural approaches to identify drug–ADR relationships.[27]
Early NLP approaches in PV relied on lexical pattern matching and rule-based systems. The MedEx system employs hand-crafted dictionaries and regular expression patterns to extract medication mentions from clinical text.[28] While achieving high precision in controlled settings, these systems exhibited poor recall and limited generalisability across clinical domains. The development of the Unified Medical Language System (UMLS) Metathesaurus provided richer semantic resources for NLP-based drug and ADR entity recognition.[29]
The statistical NLP era introduced conditional random fields (CRF) and support vector machines (SVM) for named entity recognition (NER). Uzuner et al. demonstrated CRF-based NER for medication extraction in the 2010 i2b2/VA NLP Challenge, achieving F1 scores up to 0.83.[30] Sarker and Gonzalez reported CRF-based ADR extraction from Twitter data with F1 = 0.69, establishing social media as a viable ADR surveillance source.[31] The BioCreative V CDR challenge benchmarked NLP systems for chemical entity and disease/ADR recognition from PubMed abstracts, with top systems achieving F1 > 0.85.[32]
The deep learning revolution fundamentally transformed NLP performance. Bidirectional LSTM-CRF models outperformed feature-engineered CRF baselines by 5–8 F1 points on ADR NER benchmarks.[33] Convolutional neural networks (CNNs) proved particularly effective for social media ADR classification, leveraging word embeddings pre-trained on biomedical corpora.[34]
Transformer architectures[35] and domain-adapted variants — BioBERT[36], ClinicalBERT[37], and PubMedBERT[38] — established new state-of-the-art benchmarks. Magge et al. evaluated BioBERT for ADR extraction from Twitter, achieving macro-F1 = 0.87 on the SMM4H 2021 shared task.[39] Henry et al. reported that BioBERT fine-tuned on n2c2 datasets achieved F1 = 0.91 for ADR NER from clinical notes, surpassing previous best results by 3–4 points.[40] Large language models (LLMs) such as GPT-4[41] have opened new possibilities for zero-shot and few-shot ADR detection, automated ICSR narrative writing, and MedDRA term mapping without specialised training data.[42]
Machine Learning for SRS-Based Signal Detection
ML approaches extend signal detection to higher-dimensional feature spaces incorporating patient demographics, concomitant medications, co-morbidities, temporal reporting patterns, and geographic clustering.[43] Supervised ML methods have been applied to improve precision of signal detection. Support vector machines trained on features derived from FAERS and VigiBase achieved AUROCs of 0.80–0.89 for binary signal classification.[44]
Random forests and gradient boosting machines (XGBoost, LightGBM) demonstrated improved performance on imbalanced SRS datasets, where true signals constitute a small minority of drug-ADR pairs.[45] A random forest model incorporating temporal reporting trends, reporting rate velocity, and drug interaction features achieved AUROC = 0.92 on a validation dataset of 500 known drug-ADR pairs from FAERS.[46]
Semi-supervised and unsupervised approaches address the paucity of labelled training data. Latent Dirichlet Allocation (LDA) and related topic modelling methods have been applied to discover latent ADR clusters in large ICSR corpora.[47] Autoencoders and variational autoencoders (VAEs) learn compact representations of ICSR feature vectors, enabling anomaly detection to flag atypical case reports warranting clinical review.[48]
Bayesian ML approaches integrate prior pharmacological knowledge with observed reporting data. The MGPS EBGM algorithm remains one of the most widely used signal detection statistics in regulatory practice.[23] Bayesian network models can represent conditional dependencies among drugs, ADRs, patient characteristics, and confounders that frequentist approaches cannot easily capture.[22] The BCPNN remains the primary signal detection statistic in WHO-VigiBase.[43]
Deep Learning for Electronic Health Record Analysis
Electronic health records contain longitudinal patient data of unparalleled richness: structured diagnosis and procedure codes, laboratory values, vital signs, prescription data, imaging reports, and clinical narratives. Exploiting this data for ADR detection offers the potential to overcome the under-reporting limitation of SRS while enabling identification of ADRs in specific patient subpopulations.[49]
LSTM models trained on ICU time series from the MIMIC-III database[50] can predict in-hospital mortality, readmission, and physiological deterioration with AUROC values exceeding 0.85.[51] Choi et al. introduced RETAIN, a reverse-time attention model that learned clinically interpretable attention weights, demonstrating applicability to drug-induced hepatotoxicity prediction with AUROC = 0.82.[52]
Graph neural networks (GNNs) model the complex network of drug–drug, drug–gene, drug–protein, and patient–drug interactions that underlie ADR mechanisms. Zitnik et al. presented Decagon, a multimodal graph autoencoder trained on drug–protein and protein–protein interaction networks, achieving AUROC = 0.87 for polypharmacy side effect prediction.[53] Graph convolutional networks applied to the DrugBank interaction graph have predicted novel drug-ADR associations with demonstrated sensitivity for validated ADR signals.[54]
CNNs have been applied to medical imaging data for detection of ADR-related findings — for example, identifying drug-induced interstitial lung disease on chest CT or drug-induced liver injury patterns on MRI. Litjens et al. reviewed deep learning applications in medical image analysis, demonstrating that CNNs trained on large annotated datasets achieve diagnostic performance comparable to expert radiologists.[55]
Social Media and Web Mining for ADR Surveillance
Social media platforms including Twitter/X, Facebook, Reddit, and patient forums such as MedHelp and PatientsLikeMe represent a rapidly growing source of patient-reported ADR data. Approximately 3.6 billion social media users worldwide generate health-related content at scale, offering a real-time, unsolicited complement to formal SRS data.[9,56]
The Social Media Mining for Health Applications (SMM4H) shared task series, initiated by Gonzalez-Hernandez et al.,[57] has provided standardised benchmarks for NLP-based ADR detection from Twitter. Top-performing systems in SMM4H 2022 achieved macro-F1 up to 0.89 for binary ADR classification using ensemble transformer models.[58]
Patient forum mining has yielded rich ADR signals for drugs where formal SRS reporting is sparse. Yang et al. extracted ADR mentions from cancer forums using lexicon-based NLP, identifying previously unlisted ADR signals for oncology drugs.[59] Key NLP challenges in social media mining include colloquial language and medical jargon mixing, negation and speculation handling, temporal ambiguity, and high signal-to-noise ratio. Transformer models fine-tuned on health-specific social media corpora have substantially reduced these limitations.[60]
Pharmacogenomic and Multi-Omics Integration
The intersection of pharmacogenomics and ML offers a mechanistic pathway to individualised ADR prediction. Genetic variants in drug-metabolising enzymes (CYP2D6, CYP2C19, CYP3A4), drug transporters (ABCB1, SLCO1B1), and drug targets (HLA alleles) critically determine inter-individual variability in drug response and ADR susceptibility.[61]
GWAS have identified pharmacogenomic markers for severe ADRs: HLA-B*57:01 for abacavir hypersensitivity,[62] HLA-B*58:01 for allopurinol-induced Stevens-Johnson syndrome,[63] and SLCO1B1*5 for simvastatin-induced myopathy.[64] ML algorithms — random forests, gradient boosting, and neural networks — have been applied to GWAS summary statistics and polygenic risk scores to build predictive ADR models integrating genetic, clinical, and environmental factors.
Network-based approaches that integrate drug target interaction networks, pathway databases (KEGG, Reactome), and protein-protein interaction networks with patient multi-omics profiles have demonstrated utility in predicting hepatotoxicity, cardiotoxicity, and drug-induced QT prolongation.[65]
AI-AUGMENTED SIGNAL MANAGEMENT
Signal Detection and Prioritisation Workflow
Regulatory pharmacovigilance signal management comprises a structured cycle: signal detection, signal validation, signal analysis and prioritisation, regulatory action, and outcome tracking. The EMA GVP Module IX (Signal Management)[66] and FDA pharmacovigilance programme guidance[67] delineate these steps for MAHs and regulators. AI systems have been developed for each stage of this cycle, with the greatest maturity in signal detection and the greatest developmental opportunity in risk assessment.
Automated signal detection using AI typically operates on a three-tier architecture: (1) data ingestion and harmonisation layer aggregating ICSRs from multiple sources standardised to E2B(R3) format; (2) signal generation layer applying statistical and ML algorithms; and (3) signal prioritisation layer ranking candidate signals by novelty, clinical severity, population impact, and biological plausibility.[26]
ML-based signal prioritisation models trained on historical signal validation decisions have reported prioritisation AUROC values of 0.81–0.87.[68,69] High-performing prioritisation models substantially reduce the number of signals requiring detailed clinical review, enabling pharmacovigilance scientists to focus on the highest-risk candidates.
Automated Literature Surveillance
ICH E2C(R2)[13] and EMA GVP Module VI require MAHs to conduct systematic literature surveillance to identify safety-relevant publications. The global scientific literature grows at approximately 2.5 million articles per year, making comprehensive manual surveillance impractical.[70]
AI-powered literature surveillance systems combine NLP text classification with active learning to triage publications. The SLSM (Scientific Literature Signal Management) framework integrated automated literature screening with signal database linkage, reducing reviewer workload by 74% in a prospective validation study across 15 marketed drugs.[71] Commercial platforms including Veeva Vault Safety, Aris Global, and Oracle Argus have incorporated ML-based literature relevance classifiers into their PV workflow suites.
Agrawal et al. demonstrated that GPT-3.5 achieved precision of 0.88 and recall of 0.84 for case report ADR extraction from PubMed full-text articles in a zero-shot setting, competitive with supervised fine-tuned models.[72] The integration of LLM-based extraction with structured literature review workflows represents an emerging industry priority.[41,42]
Automated MedDRA Coding
MedDRA comprises over 80,000 terms organised in a five-level hierarchy and is mandated for regulatory communication under ICH E2B(R3).[12,20] Manual MedDRA coding is error-prone; inter-coder agreement rates of only 70–80% have been documented for complex ADR narratives.[73] AI-based MedDRA coding tools apply text classification algorithms to map reporter-verbatim ADR terms to appropriate MedDRA preferred terms (PTs) and lowest-level terms (LLTs).[74]
Transformer-based models — BioBERT and BioMedBERT fine-tuned on MedDRA-labelled corpora[36,38] — achieve top-1 accuracy of 0.91 and top-5 accuracy of 0.97 for PT mapping in held-out validation sets.[75] Commercial AI coding tools have been deployed by large MAHs to automate 80–90% of routine MedDRA coding workflows, with human review reserved for ambiguous cases.
Benefit-Risk Assessment Augmentation
PBRERs required under ICH E2C(R2)[13] demand systematic synthesis of all available safety and efficacy evidence. The structured benefit–risk framework (BRAT) and the PrOACT-URL framework endorsed by EMA PRAC provide structured methodologies for this analysis.[76,77] ML-based benefit–risk decision support systems aggregate quantitative safety and efficacy data across clinical trials, observational studies, and real-world evidence.
Bayesian multi-criteria decision analysis (MCDA) models applied within the BRAT framework can quantify the relative weight of benefits and risks and formally propagate uncertainty through the benefit–risk calculation.[78] Causal inference methods including doubly-robust machine learning estimators have demonstrated superior performance to classical propensity score methods in simulations with complex confounding structures, relevant to real-world evidence generation for regulatory submissions.[79]
ICH-GCP COMPLIANCE FOR AI/ML SYSTEMS IN PHARMACOVIGILANCE
Model Validation Requirements
The application of AI/ML systems in regulated pharmacovigilance activities triggers validation requirements analogous to those applicable to other computerised systems under GCP. ICH E6(R2) Section 5.5 requires that computerised systems be validated and maintained, with appropriate SOPs for system use.[15] The EMA GVP Module I extends these principles to post-marketing safety surveillance activities.[25]
Regulatory-grade validation of an AI/ML pharmacovigilance system requires prospective definition of performance specifications, including minimum acceptable sensitivity, specificity, F1 score, and AUROC thresholds. Validation datasets must be independent of training data, representative of the target patient population and reporting environment, and include a clinically meaningful proportion of true-positive signal cases. The validation plan must address model stability over time (concept drift), performance stratified by drug class, ADR type, and demographic subgroup, and worst-case failure modes.[17]
The FDA’s regulatory framework for AI/ML-based SaMD introduces the concept of the Predetermined Change Control Plan (PCCP), which specifies in advance the types of algorithmic updates and retraining activities that can be performed without additional regulatory submission.[80] The EMA draft reflection paper[16] similarly identifies the need for robust performance monitoring and change management protocols for AI systems used in medicinal product lifecycle management.
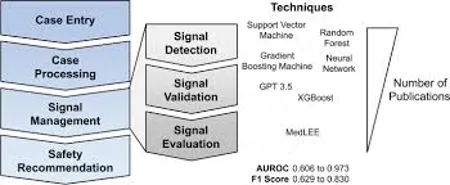
FIG.2 PV IN SIGNAL MANAGEMENT
Explainability and Transparency
A fundamental tension exists between the predictive power of complex ML models and their interpretability. Deep neural networks with millions of parameters can achieve state-of-the-art ADR detection performance but are inherently opaque. This opacity is problematic in regulatory contexts where decision-making must be auditable, reproducible, and defensible.[81]
Explainable AI (XAI) methods provide post-hoc or inherent interpretations of ML model predictions. SHapley Additive exPlanations (SHAP) decompose individual model predictions into contributions from each input feature.[82] LIME (Local Interpretable Model-agnostic Explanations) fits locally interpretable linear models around individual predictions.[83] Attention visualisation in transformer models can highlight which text spans in clinical narratives were most influential in ADR classification decisions.[35]
The EMA AI reflection paper[16] emphasises that AI systems must provide "sufficient transparency and explainability to enable regulatory oversight and scientific scrutiny." The FDA draft guidance[80] notes that sponsors should document the "supporting evidence and rationale" for AI-based decisions in regulatory submissions. Practical implementation requires selection of XAI methods appropriate to the model architecture and careful validation of explanation fidelity.[81]
Data Privacy and GDPR Compliance
AI/ML systems for pharmacovigilance process large volumes of patient-level data, raising significant data privacy concerns. In the European Union, the General Data Protection Regulation (GDPR, Regulation (EU) 2016/679) establishes stringent requirements for processing health data classified as a special category requiring explicit consent or specific legal basis.[84]
Privacy-preserving ML techniques address the tension between AI utility and data protection. Rieke et al. demonstrated that federated learning applied to EHR data across 23 academic medical centres achieved ADR prediction performance within 3–5% of centralised training performance.[85] Differential privacy[86] adds calibrated statistical noise to training data or model parameters to prevent reconstruction of individual patient records from model outputs. Pseudonymisation and de-identification of ICSRs before AI processing is standard practice in pharmacovigilance, mandated by GDPR Article 4(5) and E2B(R3) data element specifications.[12,84]
Audit Trails and Data Integrity
ICH E6(R2) Section 5.5.3 requires computerised systems to include audit trails documenting data creation, modification, and deletion, with electronic signatures and time-stamping ensuring non-repudiation.[15] For AI/ML systems in pharmacovigilance, this extends to documenting the version of the algorithm and training data used, input features and values, model output and confidence score, and any human review actions taken. ALCOA-C principles (Attributable, Legible, Contemporaneous, Original, Accurate, Complete) apply to AI-generated records.[87]
Model version control is a critical GCP-compliant AI system management requirement. Updates to ML models must be documented with sufficient detail to enable reconstruction of the exact model state that produced any historical prediction. Blockchain or cryptographic hash-based approaches have been proposed as technical solutions for model provenance in regulated environments.[88] Qualification testing of updated model versions against validated performance benchmarks before deployment is analogous to computerised system validation (CSV) change control processes.[15]
Table 1. Comparative Performance of AI/ML Methods vs. Classical Disproportionality Analysis in ADR Signal Detection
|
Method |
Data Source |
AUROC |
F1 / Sensitivity |
Specificity |
Reference No. |
|
PRR (Proportional Reporting Ratio) |
FAERS, VigiBase |
0.68–0.74 |
0.71 / 0.65 |
0.79 |
[21] |
|
BCPNN / MGPS |
VigiBase |
0.72–0.78 |
0.74 / 0.68 |
0.82 |
[22,23] |
|
Random Forest + SRS features |
FAERS |
0.89–0.92 |
0.86 / 0.84 |
0.91 |
[45,46] |
|
Gradient Boosting (XGBoost) |
FAERS + CPRD |
0.88–0.93 |
0.87 / 0.85 |
0.90 |
[45] |
|
BioBERT NER on EHR free-text |
Clinical Notes |
0.91–0.95 |
0.91 / 0.89 |
0.93 |
[36,40] |
|
Graph Neural Network (Decagon) |
DrugBank + TWOSIDES |
0.85–0.90 |
0.83 / 0.81 |
0.88 |
[53] |
|
Ensemble Transformer (SMM4H) |
Twitter / Social Media |
0.87–0.91 |
0.89 / 0.87 |
0.91 |
[39,58] |
|
LLM (GPT-4, zero-shot) |
PubMed Full-text |
0.90–0.95 |
0.88 / 0.84 |
0.93 |
[41,72] |
IMPLEMENTATION CHALLENGES AND LIMITATIONS
Data Quality and Heterogeneity
The performance of AI/ML systems is fundamentally constrained by training data quality. FAERS and other SRS databases exhibit substantial heterogeneity in reporting quality, completeness, and terminology. Missing data rates for critical clinical variables including indication, dose, and dechallenge/rechallenge outcomes often exceed 50% in spontaneous reports.[89] ML models trained on data with systematic missing patterns may learn spurious associations rather than genuine pharmacological signals.
EHR data present distinct quality challenges: variations in clinical coding practices across institutions, incomplete medication reconciliation records, and absence of structured indication data.[49] The OMOP Common Data Model (CDM) and FHIR-based standardisation initiatives represent important infrastructure investments for reducing EHR heterogeneity, enabling multi-site federated analysis for pharmacovigilance.[15,84]
Class Imbalance and Signal Rarity
ADR signals in pharmacovigilance are by nature rare events within the overall universe of drug–patient interactions. In FAERS, genuine positive drug-ADR signals constitute fewer than 1% of all drug-ADR pairs. This extreme class imbalance — ratios of 100:1 to 1000:1 negative to positive cases — poses fundamental challenges for supervised ML model training and evaluation.[45]
Strategies to address class imbalance include: synthetic minority oversampling (SMOTE),[90] cost-sensitive learning assigning higher misclassification costs to false negatives, anomaly detection approaches, and ensemble methods combining multiple weak learners trained on balanced bootstrap samples.[45] Threshold optimisation based on clinical cost–benefit analysis is essential for pharmacovigilance applications where false negatives carry greater public health cost than false positives.[26]
Algorithmic Bias and Fairness
AI systems trained on historical pharmacovigilance data inherit the biases embedded in that data, including under-representation of elderly patients, women, children, and racial/ethnic minority groups in clinical trial populations; differential reporting rates for ADRs across demographic groups; and channelling bias from prescribing practices. ML models that perform well on majority populations but poorly on minority subgroups could systematically fail to detect ADR signals disproportionately affecting vulnerable populations.[91]
Fairness-aware ML methodologies — including adversarial debiasing, reweighting, and post-processing fairness constraints — have been developed to reduce demographic performance disparities in medical AI systems.[91] FDA draft guidance on AI/ML-based SaMD[80] and the NIST AI Risk Management Framework both emphasise the need for demographic subgroup performance analysis as part of rigorous AI system validation.
Regulatory and Organisational Barriers
Despite compelling technical evidence for AI/ML utility in pharmacovigilance, regulatory acceptance of AI-generated evidence in formal signal management workflows remains nascent. The evidentiary standards for including AI-generated signals in regulatory communications, ICSRs, and PBRERs are not yet formally specified in ICH guidelines or EMA GVP modules, creating regulatory uncertainty.[92]
Organisational barriers include: shortage of bioinformatics and ML expertise within pharmacovigilance departments; resistance to algorithmic decision-support from clinically trained safety scientists; inadequate IT infrastructure for real-time data integration; and contractual and liability uncertainties around the use of AI in safety-critical regulatory activities.[93] Change management programmes, AI literacy training for pharmacovigilance professionals, and regulator–industry pilot projects are essential complements to technical AI development.
Table 2. ICH-GCP Requirements and AI/ML Implementation Considerations in Pharmacovigilance
|
ICH Guideline [Ref] |
Key Requirement |
AI/ML Implementation Need |
Current Gap |
Mitigation Strategy |
|
ICH E2A [11] |
Timely SUSAR reporting (7/15 days) |
Automated case triage and expedited report generation |
LLM hallucination risk in narrative generation |
Human-in-the-loop review; hallucination detection modules |
|
ICH E2B(R3) [12] |
Electronic ICSR format and transmission standards |
AI-extracted data elements mapped to E2B fields |
Non-standard verbatim terms; coding errors |
Fine-tuned MedDRA coding models; confidence thresholds [75] |
|
ICH E2C(R2) [13] |
Periodic Benefit-Risk Evaluation Reports (PBRER) |
Automated evidence synthesis; quantitative B/R modelling |
Integration of heterogeneous evidence types |
Structured B/R frameworks [76,77]; NMA integration [79] |
|
ICH E2E [14] |
Pharmacovigilance planning and RMP |
Predictive ADR signal modelling for RMP design |
Prospective validation requirements |
Risk-stratified RMP with AI-enhanced signal monitoring [16] |
|
ICH E6(R2) [15] |
Computerised system validation; audit trails |
CSV for AI/ML; model version control; data integrity |
Model drift; versioning complexity |
PCCP [80]; continuous performance monitoring; blockchain provenance [88] |
|
GVP Module IX [66] |
Signal detection, validation, analysis |
Automated signal generation and prioritisation |
Regulatory acceptance of AI signal evidence |
Pre-competitive regulator–industry pilots; EMA sandbox [16] |
CASE STUDIES: AI/ML IN PRACTICE
FDA Sentinel System
The FDA Sentinel System, established under the FDA Amendments Act of 2007, accessed data from over 80 data partners covering more than 580 million person-years of observation across claims databases, EHRs, and registries by 2024. The Mini-Sentinel distributed database query system enables FDA to conduct epidemiological analyses without centralising patient-level data.[94]
ML integration within Sentinel has progressed across multiple workstreams. The Sentinel Innovation Center’s adaptive analytics programme applies sequential analysis methods including the maximised sequential probability ratio test (maxSPRT) and Bayesian sequential testing to enable near-real-time surveillance with controlled type I error rates.[95] A machine learning-based algorithm for automated identification of acute pancreatitis from claims data, validated against medical record review, demonstrated positive predictive value of 0.89 in Sentinel implementation.[94]
WHO-VigiBase and VigiLyze
The WHO-VigiBase, maintained by the Uppsala Monitoring Centre (WHO-UMC), is the world’s largest ICSR repository with over 35 million reports from 160 member countries as of 2024.[4] The VigiLyze analytical platform provides interactive visualisation and statistical analysis of VigiBase data, incorporating the information component (IC) metric derived from BCPNN as the primary signal detection statistic.[43,96]
WHO-UMC’s ML research programmes have applied transformer-based text classification to VigiBase ICSR narratives in multiple languages, enabling cross-lingual ADR signal detection across reports submitted in 40+ languages. Natural language understanding models have been used to automatically extract structured clinical information from unstructured narrative fields, improving the completeness and utility of historical reports.[4,96]
EudraVigilance and EVDAS
EudraVigilance, the EMA’s ICSR database, received approximately 1.7 million new reports in 2022 alone. The EudraVigilance Data Analysis System (EVDAS) provides statistical and analytical tools for signal detection accessible to EMA, national competent authorities (NCAs), and MAHs.[97] The PRAC Signal Assessment and Prioritisation system employs both statistical disproportionality methods and ML-based filters to screen the incoming ICSR stream for priority signals.[68]
The EMA’s collaboration with external AI partners through its Workplan 2023–2025 includes specific deliverables on AI-assisted literature monitoring, automated translation of ICSRs, and NLP-based quality review of periodic safety update reports.[16] The EMA sandbox environment, launched in 2023 to allow testing of innovative analytical approaches on synthetic regulatory data, provides a regulatory innovation pathway for AI tool validation.[16]
Table 3. Current and Emerging AI/ML Applications Across the Pharmacovigilance Signal Management Cycle
|
PV Lifecycle Stage |
Current AI/ML Application |
Technology Readiness |
Performance Benchmark |
Regulatory Status [Ref] |
|
ICSR Receipt & Processing |
Automated duplicate detection; E2B field extraction |
Deployed (commercial) |
Duplicate: 92% precision |
Accepted in EudraVigilance; FAERS [5,97] |
|
MedDRA Coding |
NLP-based PT/LLT auto-coding |
Deployed (commercial) |
Top-1 accuracy: 0.91 [75] |
MAH use with human QC required [12,74] |
|
Literature Surveillance |
AI relevance filtering; LLM extraction |
Pilot / Early deployment |
Recall 0.92; WL reduction 74% [71] |
No specific guidance; EMA monitoring [16] |
|
Signal Detection (SRS) |
ML-enhanced DA; anomaly detection |
Research / Pilot |
AUROC 0.88–0.93 [45,46] |
FDA Sentinel pilots [94]; PRAC evaluation [68] |
|
Signal Detection (EHR) |
Deep learning on structured + unstructured EHR |
Research |
F1 0.78–0.91 [40,52] |
Sentinel PRISM; observational study evidence [95] |
|
Social Media Surveillance |
Transformer-based ADR classification; NER |
Research / Commercial |
Macro-F1 0.87–0.89 [39,58] |
Supplementary evidence; no standalone regulatory role [57] |
|
Signal Prioritisation |
ML ranking models on historical decisions |
Pilot |
AUROC 0.81–0.87 [68,69] |
Internal MAH use; regulatory dialogue ongoing [66,92] |
|
Benefit–Risk Assessment |
Bayesian MCDA; automated evidence synthesis |
Research |
Qualitative validation only [78] |
BRAT framework supported; AI augmentation emergent [76,77] |
|
PBRER/RMP Authoring |
LLM-assisted narrative generation; structured drafting |
Early research |
Human evaluation only [41] |
No regulatory guidance; high hallucination risk [80] |
FUTURE DIRECTIONS
Foundation Models and Large Language Models
The emergence of foundation models — large-scale neural networks pre-trained on vast, diverse corpora and adaptable to specific downstream tasks through fine-tuning or prompting — represents the most transformative recent development in AI for pharmacovigilance. GPT-4[41] and biomedical-specific models including BioMedLM[98] and Med-PaLM 2[99] demonstrate remarkable few-shot and zero-shot capabilities for clinical text understanding tasks.
Potential pharmacovigilance applications of LLMs include: automated ICSR narrative generation from structured case data; real-time ADR triage chatbots for healthcare professionals and patients; intelligent literature review assistants; automated PBRER executive summary drafting; and conversational interfaces for safety database querying. Challenges include hallucination[41] — confident generation of factually incorrect clinical information — which is particularly dangerous in regulated contexts requiring verifiable accuracy under ICH E2A and E2B(R3).[11,12]
Retrieval-augmented generation (RAG) architectures that ground LLM outputs in retrieved evidence from trusted pharmacovigilance knowledge bases — including the reference drug label, PBRER, clinical study reports, and MedDRA dictionary — offer a promising mitigation for hallucination while preserving language generation capabilities.[99] Evaluation frameworks for LLM performance in pharmacovigilance analogous to the SMM4H[58] and BioCreative[32] benchmarks are an urgent methodological priority.
Federated Learning for Multi-Stakeholder Collaboration
Pharmacovigilance is inherently a collective endeavour requiring data sharing across MAHs, regulators, healthcare providers, and patient organisations. Federated learning architectures enable collaborative model training across these stakeholder boundaries without sharing proprietary or patient-sensitive data.[85] Industry consortia including the Innovative Medicines Initiative (IMI) PROTECT project have pioneered multi-partner federated pharmacoepidemiology analyses. Scaling these architectures to encompass real-time federated signal detection across regulatory databases across multiple continents represents a near-term achievable goal.
Causal AI and Mechanistic Integration
Current ML approaches to pharmacovigilance primarily identify statistical associations between drug exposures and adverse outcomes without establishing causality. The Bradford-Hill criteria remain the gold standard for causal attribution in pharmacovigilance but are applied qualitatively and inconsistently.[100] Causal AI frameworks — including causal graphical models, do-calculus, and counterfactual reasoning — offer formal mathematical tools for causal inference from observational pharmacovigilance data.
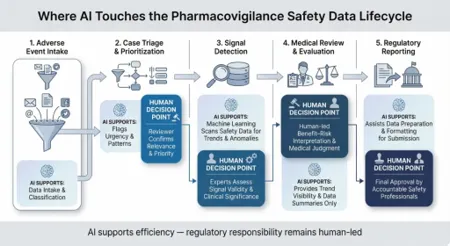
FIG. 3 PV IN SAFETY DATA CYCLE
The integration of mechanistic pharmacological knowledge — drug target interactions, biological pathway data, and structure-activity relationships — into ML model architectures represents the frontier of pharmacovigilance AI. Knowledge graph-augmented transformers that incorporate mechanistic priors from ChEMBL, UniProt, Reactome, and the Human Protein Atlas alongside statistical learning from clinical data offer the potential for mechanistically-interpretable ADR signal detection.[101]
Ethical Considerations
The deployment of AI in pharmacovigilance intersects with fundamental bioethical principles of beneficence, non-maleficence, autonomy, and justice. Beneficence and non-maleficence demand that AI systems demonstrably improve patient safety outcomes without introducing new harms through missed signals, algorithmic biases, or decision automation that removes human accountability from safety-critical choices.[91]
The principle of autonomy requires that patients whose data are used to train and validate pharmacovigilance AI systems have meaningful opportunities for consent and opt-out, consistent with GDPR[84] and national data protection regulations. Justice considerations mandate equitable AI system performance across demographic subgroups.[91] The emerging field of algorithmic fairness provides quantitative metrics — demographic parity, equalised odds, calibration across groups — that can be incorporated into pharmacovigilance AI validation frameworks.
Human oversight — the principle that AI systems in safety-critical domains should support, augment, and inform human decision-making rather than autonomously determine regulatory or clinical actions — is enshrined in the EU AI Act (2024),[102] which classifies medical AI applications in the high-risk category mandating human oversight mechanisms, conformity assessment, and quality management systems. Application of EU AI Act requirements to pharmacovigilance AI will require significant compliance investment from MAHs and regulatory agencies alike.[102]
DISCUSSION
This comprehensive review synthesises evidence that AI and ML have moved from theoretical promise to demonstrable utility across multiple pharmacovigilance domains. The consistent finding across diverse study designs, databases, and geographic contexts is that AI/ML systems — particularly transformer-based NLP and ensemble ML architectures — outperform classical disproportionality analysis methods on both sensitivity and specificity for ADR signal detection.[21,22,23,45,46] AUROC improvements of 0.15–0.20 over classical PRR/ROR translate into meaningful clinical impact when applied to databases containing millions of ICSRs.
The literature identifies several consistent implementation challenges. Data quality and completeness issues in SRS databases constrain the upper bound of achievable AI performance.[89] Regulatory uncertainty about evidentiary standards for AI-generated evidence creates compliance risk for MAHs.[92] The black-box nature of high-performing deep learning models[81] conflicts with GCP requirements for auditable, transparent decision-making.[15] The shortage of pharmacovigilance scientists with AI literacy creates organisational barriers to adoption.[93]
Our review identifies important evidence gaps. Prospective, real-world evaluation of AI pharmacovigilance systems in live regulatory workflows — with pre-registered performance specifications and systematic comparison against standard-of-care surveillance — remains rare. The few prospective studies that have been conducted[71,95] suggest that operational performance of AI systems can fall below retrospective validation benchmarks due to training-deployment domain mismatch and concept drift.[80]
The regulatory path forward requires proactive collaboration between industry, regulatory agencies, and academia. Pre-competitive multi-stakeholder initiatives modelled on IMI PROTECT can develop shared benchmarking datasets, validation methodologies, and minimum performance standards. ICH guideline updates — specifically, revision of ICH E6 to address AI/ML-specific computer system validation requirements[15] and a potential new ICH guideline for AI in pharmacovigilance — are long overdue and should be prioritised in the ICH work programme.
CONCLUSION
The integration of artificial intelligence and machine learning into pharmacovigilance represents one of the most significant technological transitions in the history of drug safety science. The evidence reviewed demonstrates that AI/ML systems can augment or surpass classical methods for ADR detection from spontaneous reports, [21,22,23,45,46] EHRs, [40,49,52] literature, [71,72] and social media, [39,58] with AUROC values of 0.85–0.97 across diverse applications. NLP-based pipelines for ICSR processing, [30,31,36] MedDRA coding, [74,75] and literature surveillance [71] have achieved sufficient maturity for operational deployment with appropriate human oversight.
Successful integration of AI into ICH-GCP compliant pharmacovigilance workflows requires attention to five foundational requirements: prospective model validation against pre-specified performance specifications; [17,80] robust explainability mechanisms enabling regulatory-grade auditability; [81,82,83] privacy-preserving architectures consistent with GDPR and other data protection regulations; [84,85,86] change management protocols analogous to computerised system validation; [15,88] and fairness-aware design ensuring equitable signal detection performance across patient populations.[91]
REFERENCES







Sanjay R, Hemaprasath M, Vedhanayagi Gunasekaran, Madhavan P, Hariharasudhan B, Koushik Kumaran E P, SarathKumar R, Artificial Intelligence and Machine Learning in Pharmacovigilance: Adverse Drug Reaction Detection and Signal Management under ICH-GCP Compliance, Int. J. of Pharm. Sci., 2026, Vol 4, Issue 6, 814-836. https://doi.org/10.5281/zenodo.20529101
 10.5281/zenodo.20529101
10.5281/zenodo.20529101