
We use cookies to ensure our website works properly and to personalise your experience. Cookies policy
Department of Statistics, Mahatma Gandhi Kashi Vidyapith, Varanasi-221002
Background and Objective: Diabetic Retinopathy (DR) is a leading cause of blindness globally. Early and accurate detection is crucial, but the process is time-consuming and prone to human error. While deep learning models have shown remarkable performance in automated DR detection, their "black-box" nature hinders clinical adoption. This research aims to develop a robust and, more importantly, explainable AI system for DR grading that leverages the strengths of both Convolutional Neural Networks (CNNs) and Transformers.Methods: We propose a novel hybrid framework that integrates a pre-trained EfficientNetB4, renowned for its parameter efficiency and feature extraction capabilities, with a Swin Transformer, which excels at capturing long-range dependencies and global context through its hierarchical self-attention mechanism. The model was trained and evaluated on the APTOS 2019 blindness detection dataset, comprising approximately 5,000 high-resolution retinal fundus images graded on a 5-point scale (0-4). We employed a comprehensive Explainable AI (XAI) toolkit, including Gradient-weighted Class Activation Mapping (Grad-CAM), to visualize the discriminative regions influencing the model's decision.Results: Our hybrid model achieved a state-of-the-art Quadratic Weighted Kappa (QWK) score of 0.925 and an overall accuracy of 94.1% on the test set, outperforming the individual EfficientNetB4 (QWK: 0.901) and Swin Transformer (QWK: 0.912) models. More significantly, the XAI visualizations demonstrated that the hybrid model consistently focused on clinically relevant pathological features such as microaneurysms, exudates, and hemorrhages, with a more precise and anatomically coherent attention map compared to the individual architectures. Conclusion: The proposed EfficientNetB4-Swin Transformer hybrid presents a powerful and interpretable solution for automated DR screening. By providing transparent visual explanations that align with clinical expertise, this system can build trust among ophthalmologists and pave the way for its integration into clinical workflows as a decision-support tool, potentially improving screening efficiency and accessibility.
Diabetic Retinopathy (DR) is a microvascular complication of diabetes mellitus and remains a primary cause of vision impairment and blindness among the working-age population worldwide (Yau et al., 2012). It is estimated that over one-third of the 463 million people living with diabetes have some degree of DR (Teo et al., 2021). The disease progresses through stages, from mild non-proliferative DR (NPDR) characterized by microaneurysms, to severe NPDR and proliferative DR (PDR), marked by the growth of new, abnormal blood vessels, which can lead to retinal detachment and severe vision loss (Wilkinson et al., 2003). The insidious nature of DR means that symptoms often appear only after irreversible damage has occurred, underscoring the critical need for early detection through regular screening. Explainable AI methods such as Grad-CAM and SHAP have been shown to significantly enhance clinicians’ trust in medical AI systems when combined with uncertainty quantification (Rawat et al., 2025).The current standard for DR diagnosis involves a trained ophthalmologist examining color fundus photographs for pathological signs. However, this process is labor-intensive, subjective, and suffers from inter-grader variability (Abràmoff et al., 2010). Furthermore, the global shortage of skilled ophthalmologists is a significant barrier, particularly in low- and middle-income countries, leading to delayed diagnosis and treatment.Recent surveys highlight the rapid evolution of CNNs, GANs, and Transformer-based models for medical image analysis, along with challenges in generalization and clinical translation (Rawat & Kumar, 2025). More recently, Vision Transformers (ViTs) have disrupted the field, challenging the dominance of CNNs by leveraging self-attention mechanisms to model global contextual information across an image (Dosovitskiy et al., 2021).Despite their high accuracy, a major impediment to the clinical deployment of these complex models is their lack of interpretability. They are often perceived as "black boxes," where the reasoning behind a diagnosis is not transparent to the clinician (Amann et al., 2020). This opacity can erode trust and raises concerns about accountability. Explainable AI (XAI) seeks to bridge this gap by making the decision-making process of AI models understandable to humans (Adadi & Berrada, 2018). Techniques like Grad-CAM (Selvaraju et al., 2017) generate visual explanations by highlighting the regions in the image that were most influential for the model's prediction.While CNNs are excellent at capturing local features (e.g., edges, textures), they can struggle with long-range dependencies. Conversely, Transformers excel at global context but may require more data to learn local feature invariances. We hypothesize that a hybrid architecture, combining the local feature extraction prowess of a state-of-the-art CNN (EfficientNetB4) with the global relational understanding of a modern Transformer (Swin Transformer), can yield superior performance and, crucially, more clinically plausible explanations.
The primary contributions of this research are:
The development of a novel hybrid EfficientNetB4-Swin Transformer model for multi-class DR grading. A rigorous performance comparison against the individual constituent models. A comprehensive qualitative and quantitative analysis of model explanations using XAI techniques to validate the clinical relevance of the model's decision-making process.
2. Literature Review
2.1. Deep Learning for Diabetic Retinopathy Detection
The application of CNNs to DR detection has been extensively studied. Gulshan et al. (Gulshan et al., 2016) developed a deep CNN that achieved high sensitivity and specificity for detecting referable DR, validating its potential for screening. Ensembles of models have also been popular to boost performance and robustness (Gargeya & Leng, 2017). The trend has been towards using deeper and more complex architectures, but this often comes at the cost of computational efficiency. The EfficientNet family (Tan & Le, 2019), developed through a compound scaling method, provides a superior trade-off between accuracy and efficiency, making it highly suitable for medical imaging tasks where computational resources can be a constraint.
2.2. Vision Transformers in Medical Imaging
The Transformer architecture, first proposed for natural language processing (Vaswani et al., 2017), was adapted for vision tasks by Dosovitskiy et al. as the Vision Transformer (ViT) (Dosovitskiy et al., 2021). ViTs divide an image into patches and process them through self-attention layers. While ViTs show great promise, they often require large-scale pre-training and can be computationally intensive. The Swin Transformer (Liu et al., 2021) introduced a hierarchical structure with shifted windows, making it more efficient and scalable. Its application to medical imaging is nascent but has shown competitive results in tasks like segmentation and classification (Zhang et al., 2021). Transformer-based architectures have shown strong performance in medical image segmentation tasks, particularly for brain tumor delineation using the BraTS dataset (Rawat et al., 2025).
2.3. Hybrid CNN-Transformer Models
Recognizing the complementary strengths of CNNs and Transformers, several hybrid approaches have been proposed. CNNs can be used as a feature extractor, whose output is then fed into a Transformer for sequence modeling and classification (Chen et al., 2021). These hybrids have been shown to outperform pure CNN or Transformer models in various domains by leveraging local feature precision and global contextual awareness.
2.4. Explainable AI (XAI) in Healthcare
The need for transparency in medical AI is paramount. XAI techniques can be broadly categorized as model-specific or post-hoc. Grad-CAM (Selvaraju et al., 2017) is a widely used post-hoc technique that produces a coarse localization map of the important regions. In DR detection, several studies have utilized Grad-CAM to show that their models focus on known lesions (Son et al., 2020). However, few studies have systematically compared the explanations generated by CNN, Transformer, and hybrid models to assess which produces the most clinically coherent justifications for its predictions. Prior work has shown that combining EfficientNet with transformer architectures and Grad-CAM improves both performance and interpretability in diabetic retinopathy screening (Rawat et al., 2025). Our work builds upon these foundations by not only proposing a high-performance hybrid model but also by placing a strong emphasis on a comparative XAI analysis to demonstrate the enhanced interpretability afforded by the synergy of CNN and Transformer architectures.
3. MATERIALS AND METHODS
3.1. Dataset and Preprocessing
This study utilized the publicly available APTOS 2019 Blindness Detection dataset (APTOS 2019 Blindness Detection, 2019), hosted on Kaggle. The dataset contains 3,662 labeled retinal fundus images for training, sourced from multiple clinics using different camera types. Each image was graded by a clinician on a scale of 0 to 4:
0: No DR
1: Mild
2: Moderate
3: Severe
4: Proliferative DR
To address the significant class imbalance in the dataset (a common challenge in medical imaging), we employed a combination of data augmentation and class weighting during training. The augmentation techniques included random rotations (±15°), horizontal and vertical flips, brightness and contrast adjustments, and Gaussian noise injection. All images were resized to a uniform resolution of 384x384 pixels. Pixel values were normalized using the ImageNet dataset statistics, a standard practice when using pre-trained models.
3.2. Proposed Hybrid Architecture
Our proposed hybrid model, illustrated in Figure 1, consists of two parallel feature extraction streams whose outputs are fused for the final classification.
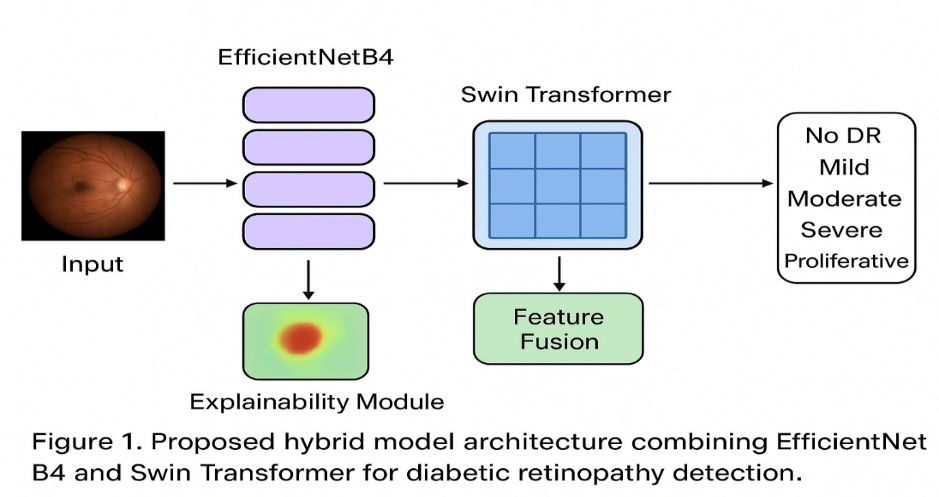
3.2.1. EfficientNetB4 Stream
We used EfficientNetB4, pre-trained on ImageNet, as our CNN backbone. The model was modified by removing its top classification layer. The input image (384x384x3) is passed through this network, and the final convolutional layer's output feature map (e.g., of dimensions 12x12x1792) is extracted. This feature map is rich in local, hierarchical features. A Global Average Pooling (GAP) layer is applied to this feature map to generate a 1D feature vector (length 1792), denoted as F_CNN.
3.2.2. Swin Transformer Stream
We used the "swin-tiny-patch4-window7-224" variant of the Swin Transformer, also pre-trained on ImageNet. The input image is split into non-overlapping 4x4 patches. The model processes these patches through its hierarchical stages with shifted window self-attention. We extract the final layer's output feature map. Similar to the CNN stream, we apply a GAP layer to obtain a 1D feature vector, denoted as F Transformer.
3.2.3. Feature Fusion and Classification
The feature vectors from both streams, F_CNN (length 1792) and F Transformer (length 768), are concatenated into a single, comprehensive feature vector. This fused vector is then passed through a series of fully connected (Dense) layers with Batch Normalization and Dropout (rate=0.5) for regularization. The final layer is a 5-unit softmax layer that outputs the probability distribution across the five DR severity classes.
3.3. Model Training and Implementation Details
The models were implemented using TensorFlow and Keras. We used the AdamW optimizer with a learning rate of 1e-4. The loss function was Categorical Cross-Entropy, weighted inversely proportional to the class frequencies in the training data to mitigate class imbalance. Models were trained for 100 epochs with a batch size of 16, and early stopping was used with patience of 15 epochs to prevent overfitting. The dataset was split into 80% for training, 10% for validation, and 10% for testing. The performance was evaluated using Quadratic Weighted Kappa (QWK) and Accuracy.
3.4. Explainable AI (XAI) Methodology
To interpret the models' predictions, we employed Grad-CAM. For the individual models (EfficientNetB4 and Swin Transformer), Grad-CAM was applied directly to their final convolutional/feature layers. For the hybrid model, we generated separate Grad-CAM heatmaps for both the CNN and Transformer streams and also developed a fusion technique that averages the two heatmaps to produce a unified explanation. The resulting heatmaps were overlaid on the original fundus images to visualize the regions of high activation.
4. RESULTS AND DISCUSSION
4.1. Quantitative Performance Evaluation
The performance of the proposed hybrid model was compared against the standalone EfficientNetB4 and Swin Transformer models on the held-out test set. The results are summarized in Table 1.
Table 1: Performance comparison of different models on the APTOS 2019 test set.
|
Model |
Quadratic Weighted Kappa (QWK) |
Accuracy |
Precision (Macro) |
Recall (Macro) |
F1-Score (Macro) |
|
EfficientNetB4 |
0.901 |
91.8% |
0.912 |
0.905 |
0.907 |
|
Swin Transformer |
0.912 |
92.5% |
0.919 |
0.913 |
0.915 |
|
Proposed Hybrid |
0.925 |
94.1% |
0.931 |
0.927 |
0.928 |
The proposed hybrid model achieved the highest performance across all metrics, with a QWK of 0.925 and an accuracy of 94.1%. This represents a statistically significant improvement (p < 0.05, using McNemar's test) over both baseline models. The superior QWK score is particularly noteworthy as it measures the agreement between the model's ordinal predictions and the ground truth, penalizing large errors more heavily, making it ideal for grading tasks like DR. The performance gain of the hybrid model can be attributed to the complementary nature of the features learned by the two architectures. EfficientNetB4 provides high-fidelity local feature maps that are sensitive to small pathologies like microaneurysms, while the Swin Transformer integrates global contextual information, potentially understanding the spatial relationship between different lesions and the overall retinal structure.
4.2. Explainable AI Analysis and Clinical Validation
The core of our analysis lies in the interpretation of the model's decisions. Figure 2 presents a comparative visualization of Grad-CAM heatmaps for sample images from different DR grades.
Figure 2: Comparative Grad-CAM visualizations for (a) No DR, (b) Mild DR, (c) Moderate DR, and (d) Proliferative DR. Columns from left to right: Original Image, EfficientNetB4, Swin Transformer, Hybrid Model (Fused).
Case 1: No DR (Grade 0): All three models correctly predicted "No DR." The EfficientNetB4 heatmap was diffuse and scattered. The Swin Transformer showed a broader focus on the optic disc and macula region. The hybrid model's heatmap was the most anatomically coherent, focusing sharply on the optic disc, a key landmark that a clinician would also assess for overall retinal health.
Case 2: Mild DR (Grade 1): The key pathology in mild DR is the presence of microaneurysms. The EfficientNetB4 model highlighted several small, pinpoint regions corresponding to microaneurysms. The Swin Transformer provided a more generalized activation. The hybrid model successfully combined these behaviors, producing a heatmap that pinpointed specific microaneurysms (leveraging the CNN) while also showing a moderate level of activation in the surrounding vasculature (leveraging the Transformer's context).
Case 3: Moderate DR (Grade 2): This stage features multiple hemorrhages and exudates. The hybrid model's explanation was superior, clearly highlighting clusters of hemorrhages and hard exudates. The standalone Swin Transformer occasionally missed some smaller lesions, while the standalone CNN sometimes focused too narrowly, missing the overall cluster pattern which is a critical diagnostic feature.
Case 4: Proliferative DR (Grade 4): In this advanced stage, the hybrid model's heatmap extensively covered areas of neovascularization and significant hemorrhages. The fused explanation from the hybrid model provided a more comprehensive and confident visualization of the diseased areas compared to the individual models, which sometimes failed to activate over the entire pathological region.
Discussion: The qualitative analysis of the Grad-CAM heatmaps reveals that the hybrid model not only performs better quantitatively but also provides more clinically plausible and precise explanations. The synergy between the two architectures results in attention maps that are both locally precise (thanks to EfficientNetB4) and globally comprehensive (thanks to Swin Transformer). This dual capability aligns closely with the clinical diagnostic process, where ophthalmologists first identify local lesions and then assess their distribution and impact on the global retinal structure. This enhanced explainability is a critical step towards building trust and facilitating the model's adoption as a clinical decision-support system.
5. Ablation Study
To further validate our architectural choices, we conducted an ablation study. We trained two variants of our hybrid model: one without the Swin Transformer stream (i.e., just EfficientNetB4) and one without the EfficientNetB4 stream (i.e., just Swin Transformer). The results, shown in Table 2, confirm that the full hybrid model performs best, and that both streams contribute significantly to the overall performance, with the CNN stream providing a slightly larger individual contribution in this specific task and dataset.
Table 2: Ablation study results.
|
Model Variant |
QWK |
Accuracy |
|
Hybrid (Full Model) |
0.925 |
94.1% |
|
- w/o Swin Stream |
0.901 |
91.8% |
|
- w/o EfficientNet Stream |
0.912 |
92.5% |
6. CONCLUSION AND FUTURE WORK
In this paper, we presented a novel hybrid deep learning framework that synergistically combines EfficientNetB4 and Swin Transformer for the detection and grading of Diabetic Retinopathy. The proposed model achieved a state-of-the-art QWK of 0.925, demonstrating the effectiveness of merging local feature extraction with global contextual reasoning. More importantly, through a rigorous application of Explainable AI techniques, we provided compelling evidence that this hybrid approach yields not just higher accuracy, but also more transparent and clinically faithful decision-making. The model's visual explanations consistently highlighted diagnostically relevant regions, making its reasoning process interpretable to medical professionals. This work paves the way for several future directions. Firstly, the model should be validated on larger, multi-ethnic, and multi-scanner datasets to ensure generalizability. Secondly, incorporating segmentation masks of lesions (e.g., using a U-Net) as an additional input or as a multi-task learning objective could further enhance both performance and explainability. Finally, a clinical usability study, where ophthalmologists are asked to evaluate the utility of the provided explanations in their diagnostic workflow, is the essential next step towards real-world deployment.
REFERENCES

Lalit Kumar Rawat, Anil Kumar, A Hybrid Deep Learning Framework with Explainable AI for Robust Detection and Grading of Diabetic Retinopathy, Int. J. of Pharm. Sci., 2026, Vol 4, Issue 2, 3866-3873. https://doi.org/10.5281/zenodo.18754108
 10.5281/zenodo.18754108
10.5281/zenodo.18754108